Patent-based Trend Analysis on Tunable Optics
Project “Patent Intelligence” uses publicly available patents to visualize trends of specific keywords in a crowd-generated patent database to monitor an ongoing technological shift within optics. For years auto-focus functionality has been accessible through a technology known as voice coil motors (VCM). In the recent years the emergence of new technologies such as liquid lenses, shape metal alloys (SMA) and other tunable optics has started to challenge VCMs position as the best solution with regards to operational specifications, optical quality and cost. In this series you won’t get any information or opinions about these technologies. Only graphs and statistics based on keyword extracted from a group of patents that has never been manually checked validated for relevancy. If a toaster patent uses the word “tunable” – you might find it in the underlying material!
For transparency all information about techniques used and data collected for analysis is shared with the hope to encourage others to participate, investigate and help us improve through feedback and ideas. Feel free to ask for a github link – there is no strings attached to either the code or data.
Data Gathering
A Collection of formal data and keywords is scraped from patents. This paragraph outlines how we find patents and sort them into group for further analysis.
Scrape the Forums
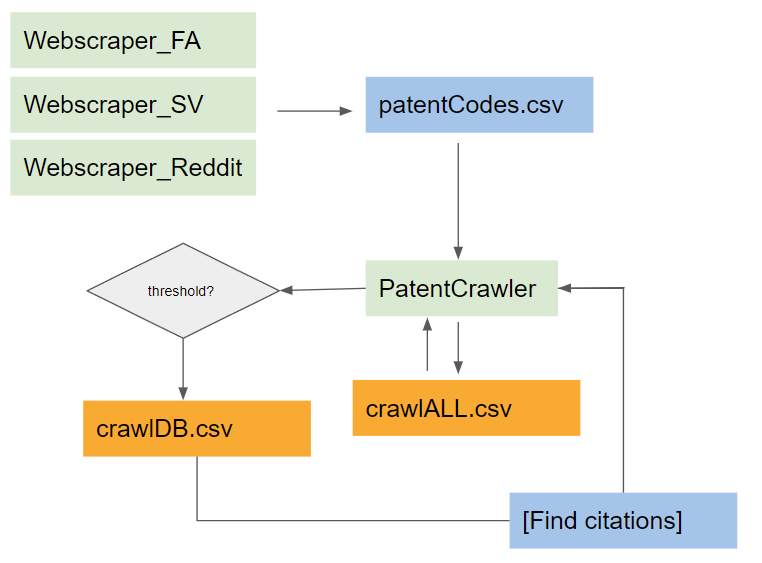
The Norwegian company Polight ASA is one of the leading companies within the space of tunable optics alongside Varioptics (Corning) and Optotune. Polight has an active base of shareholders and followers who regularly share, dissects and discusses relevant patents on several forums for clues about adoption of this technology. These forums are sources to extremely valuable information as they provide relevant patents for tunable optics stretching several years back up to today. Big kudos to those who search and share their findings, this project would truly be impossible without the continual efforts of so many individuals!
Python-based web-scraping enables automatic processing of relevant posts for forums such as Shareville, FA Forum an reddit/r/polight. Each post is processed and every hyperlink that refers to patent-sites such as espace.net or google.patents is saved to a list called patentCodes.
The list of “curated” patentCodes is downloaded from google.patents. Key pieces of information is extracted from the patents and a relevancy score is “computed”:
- Inventor and Assigned Company
- Priority Date, Published Date, Granted Date and Patent Status
- Occurrences of specific keywords (trademarks, lens types, technologies mentioned, applications, competitive technology)
- A score and relevancy judgement based on heuristically derived function
- Forward- and backward citations
If a patent has a high enough score we’ll save it to crawlDB.csv and all the citations are added to a list for further processing. This allows us to crawl related patents based on a keyword-analysis. The crawler uses the scraped list of patentCodes and scoreThreshold as input. The scraped data from every crawled patent are streamed to a file called crawlerALL.csv.
While this method is easy to implement and yields great results it is important to mention that one of the key weaknesses is the heuristically scoring method and keyword searching. False positives when searching for keywords are common. The scoring function has to to cover both regional differences among a maturity process on how to describe tunable optics. Today the scoring function is unreliable and relatively untested after the last rewrite – but with feedback with references score/patents we’re able to improve much quicker than without the feedback.
Sorting the Patents
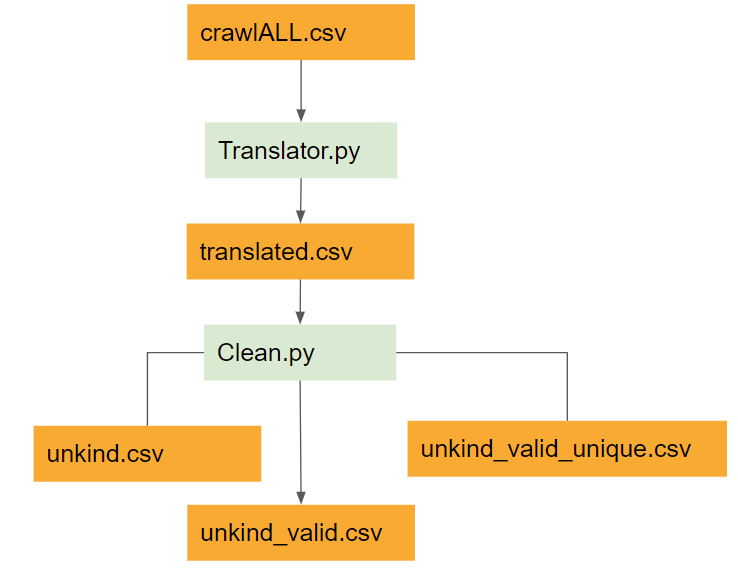
The sheer amount of irrelevant patents within the unfiltered crawlerALL.csv is significant. This comes with the territory of automated crawling. Patents has to be sorted into several sub groups based on different criteria. Examples are that a specific patent can be filed in different countries, have several versions of the same patent codes (but unique kind codes) or be a variation of another patent. All of these factors requires a conscious decision on what to use for specific analysis. Intuitively patents can be processed by:
- Enforce unique patentcodes (Remove duplicates based on kind numbers)
- Regional independent patents (Remove duplicates based on same inventor/title/pri_date)
- Valid patents (Remove patents with invalid statuses)
- Only Granted Patents
These steps can be applied to ensure some quality of each processed patent as to not provide artificially inflated numbers – now we only have false positives to account for 😉
Translation is a pain in the ass and considered the main problem with organizing and processing crawlerALL.csv data because it contains a huge number of Asian patents. In order to get information about the Assignee / Company behind the patent – the name has to often be translated with the use python (googletrans). The quality of these translations is not always “best” and the resulting name might also be of an unknown subsidiary of famous companies or straight up horrible translation of a western name. The current solution is to manually “correct” these names – but it’s still a fairly broken solution.
But let’s end this paragraph on a positive note, all the result data are now readily available as:
- crawlerALL.csv | All patents in the “Run”
- crawlerALL_translated.csv | Translated patents – may contain errors from translation
- crawlerALL_translated_valid.csv | Removal of patents with status as (withdrawn, abandoned, expired..)
- crawlerALL_translated_valid_unkind.csv | Removal of patents that share pri_date and inventor
- crawlerALL_translated_valid_unkind_unique.csv | Removal of patents that share Inventor and Title
There is definitely ways to improve this division into the grouping – for example to ensure that the newest patent with the “highest” kind code makes it to the final selection. It’s on the never ending to-do list.
How to Use the CSV Files
All the recent crawler runs are available on this link stored in folders named as (YY-MM-DD). These runs might deviate in crawler settings thus be of variable dataset sizes.
CSV files combined with Excel gives some pretty decent functionality to process this data out of the box. Go to the “Data” tab and select “Import from CSV”, this should give you a nice table with filters (Arrows on the top row). If is also recommended to use “Sort” to create multi-layer ordered CSV files combined with Filters to really get the best parts.
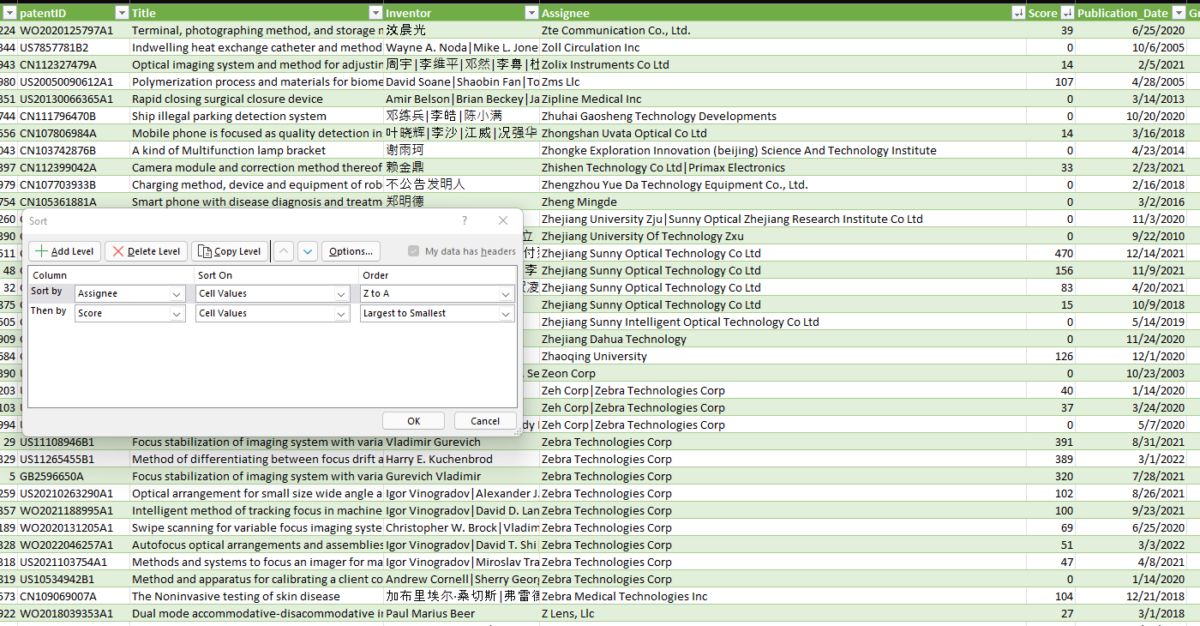
What can you do with these files?
- Identify interesting patents to study – based on date, companies and applications!
- Help us find false positives both for keyword search and scoring.
- Plot scores based on companies
- Find new companies in the data to investigate for more information – we even found a camera module by snooping around! We’re sure there is still more to discover!
- Identify shitty translations (this would be of massive help!)
- …
Let us know if you have any feedback, want to join the project or have made some cool plots with the data.
That’s it for now! Graphs and plots will shortly follow.