
Patent Analysis | New Features!
Write code, not blogposts. This has been the mantra for the last few weeks while new features and a complete re-design of the keyword search was implemented.
The code is now in beta, finally ready for larger searches than ever – I wanted to punch down a few words of the improvements and why I am feeling stoked about them.
Restart Capabilities
There are many reasons to why one would like to restart an analysis – personally I’ve experienced loss of WiFi amidst a huge run causing a loss of many hours (18) data. Of course, the crawler was modified to handle time-outs and other networking issues – but still being able start/restart a “run” at will considerably increases the sizes of searches whilst providing a redundant fail-safe to unforeseen problems as mention above.
Patents are processed in iterations and chunks. It is now possible to resume a run at any given iteration/chunk pair greatly improving flexibility for multi-session runs! No fear of using low thresholds when crawling, provided that the delete-patent threshold is so low that you only store the most relevant patents on disk 😉
Modular Scoring Protocol
Based on what should have been the next post – Keyword Scoring.!
By analysis of confirmed related patents with TLens keywords have been extracted into 5 categories
- Trademarks and Company name (Polight, TLens, Instant Focus, All-in-focus)
- Lens adjectives (tunable, liquid, adjustable, fresnel, deformable…)
- TLens related components (piezo, mems, polymer, flexible membrane…)
- Competitive Technology and Components (Liquid Lens, SMA, electrowetting, fluid chambe…)
- Intended use (in-cabin, smartphone, VR, AR, endoscopy
All keywords are associated with scoring data, which goes like this:
score += min(scoreMax, pow(occurencesOfKeyword*scoreBase, scoringExponent))
It’s a pretty simple way to include and tune a large list of keywords. For the keyword-groups 4 and 5 scoring is set to 0. The big challenge is however to find good values for the different keywords. This requires scores and patents to be scrutinized closely as scores are adjusted. An example of this file is found here.
Hopefully a job better performed by AI or any NLP solution. Looking forward to try that instead!
Search Object Structure
With searches being becoming quite dependent on scoringKeywords.xlsx, dictDB_edit.csv and scraped forum links coupled together with a bunch of files related to the restart functionality it made sense to group all these related files into a “Job Object” – basically a folder which holds the information required to perform a similar search at a later point in time. It will only be similar as patent citations has a tendency to change over time. This will allow us to compare different scoring strategies as well as ensuring some consistency in patent crawling between runs other than tweaking the threshold score.
Conceptual Overview
To give a simple overview of the flow of user generated files and scripts – I present to you – the quickest flowchart ever created:
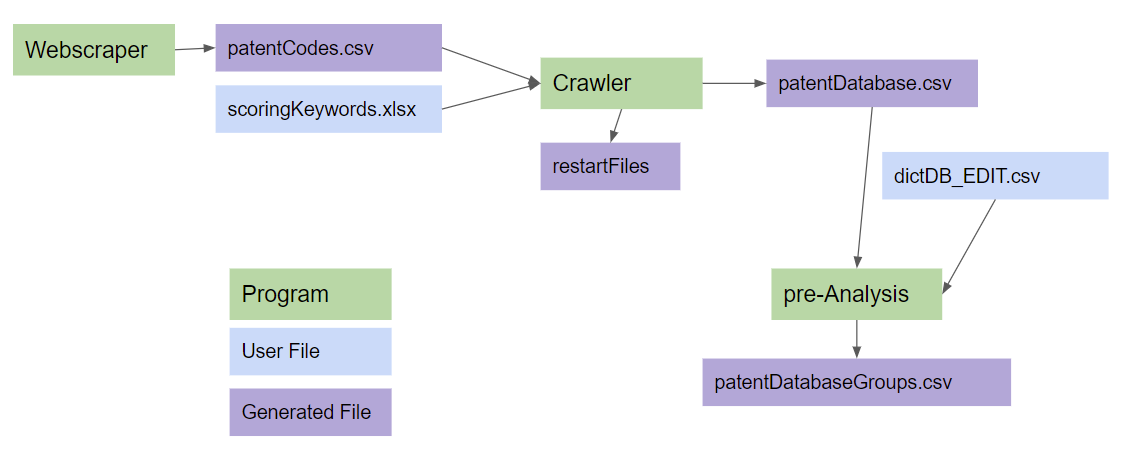
That’s it for now.
Next up is to validate and tune the scoreKeywords.xlsl and start to build a database of manually confirmed patents that can be used to extract and tune keywords and maybe even be used as training material for a future AI/NLP approach!