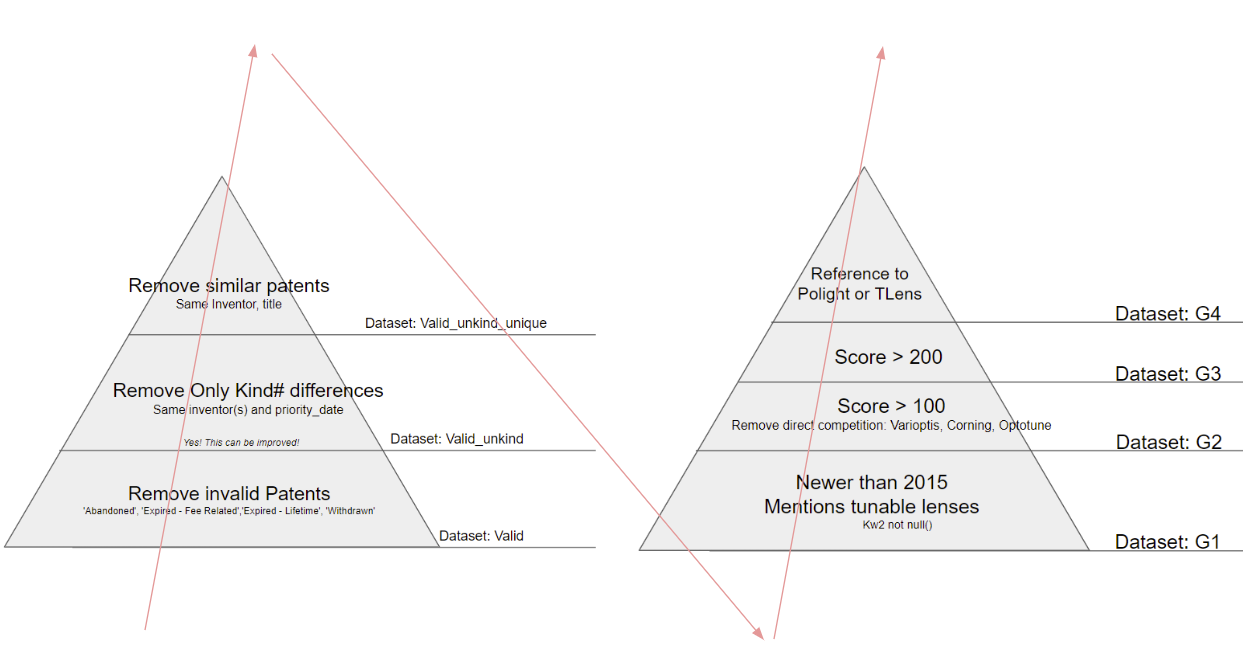
Patent Subsets based on Relevance
Naturally, it makes sense to also explain the criteria for the underlying datasets before we start having fun with plots!
Divide and Conquer | Into Subsets
The raw dataset crawlerALL.csv is translated and redundancies are removed with regard to several factors:
- Validity (is the patent discarded, abandoned etc)
- Regional Domain (same patent applied for in JP, KR and CN?)
- Kind numbers: One patent has several kind codes throughout it’s process
- Uniqueness: Same inventor, title, application date?
From this the most conservative dataset (all the above mentioned criterias) is divided into four new subsets, where the probability of TLens is greatly increased from G4 to G1. G4 includes all relevant patents for tunable optics while G2 and upwards should greatly increase relevance for TLens.

Under the assumption that the ever evolving keywords score and dictionary won’t undergo any drastic changes, the number of patents will give some slight insight in the impact of minor changes to the input file as well as the recent developments due to date at a first glance! Being able to quickly get an overview is always important data analytics.
Run Stats for 2-June 2022_Threshold 100
I performed a run with a threshold on the lower end of the scale, which is a value I truly don’t yet fully understand. The impacts of this “low” values is that it generates more and more patents for every iterations meaning it has expanding boundaries – indicating that the keywords needs to punish non-relevant patents harder if they move away from tunable optics related patents.
One example of the development of relevant subsets can be seen below:
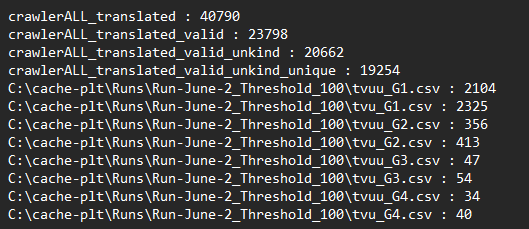
From this we can read that from nearly 40.000 patents, only 50% is considered valid and unique. From this 10% is of interest in the light of Tunable Optics (G1) with a massive dropoff to the final 34/40 patents of direct use of Polight’s Trademarks. It should be mentioned that even irrelevant patents has made it all the way to the G4 groups, and when that happens – a fix is done by editing the scoreKeyword file to add some negative points.